Beta Hat In Matrix Form

Introduction To The Hat Matrix In Regression Youtube
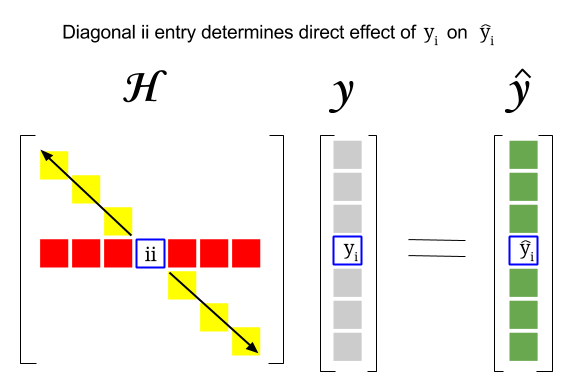
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated

How To Derive Variance Covariance Matrix Of Coefficients In Linear Regression Cross Validated

Linear Regression Using Matrix Multiplication In Python Using Numpy Python And R Tips

Matrix Dimension For Linear Regression Coefficients Artificial Intelligence Stack Exchange
Http Www Few Vu Nl Wvanwie Courses Highdimensionaldataanalysis Wnvanwieringen Hdda Lecture234 Ridgeregression 20182019 Pdf
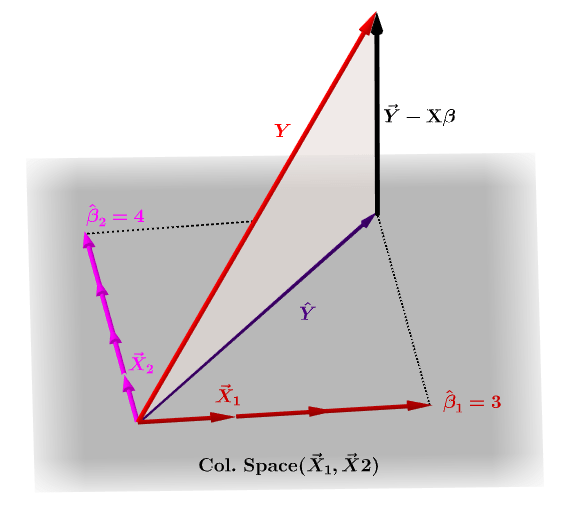
Predicted aluesv of y and beta given the sample data x.
Beta hat in matrix form. UNBIASED In order to prove that OLS in matrix form is unbiased we want to show that the expected aluev of is equal to the population coe cient of. While reading about least squares implementation for machine learning I came across this passage in the following two photos. We call this the hat matrix because is turns Ys into Ys.
We can combine the predictor variables together as matrix. Matrix notation applies to other regression topics including fitted values residuals sums of squares and inferences about regression parameters. This video derives the variance of Least Squares estimators under the assumptions of no serial correlation and homoscedastic errors.
S q u a r e d E r r o r i y i y i 2. In uence Since His not a function of y we can easily verify that mb iy j H ij. These estimates will be approximately normal in general.
HH H H projects y onto the column space of X. First we must nd what is. The OLS estimator written as a random variable is given by.
It follows that the hat matrix His symmetric too. These estimates are normal if Y is normal. Hat Matrix same as SLR model Note that we can write the fitted values as y Xb XX0X 1X0y Hy where H XX0X 1X0is thehat matrix.
Just note that yˆ y e I My Hy 31 where H XX0X1X0 32 Greene calls this matrix P but he is alone. In the standard linear regression model we have E ε. H is a symmetric and idempotent matrix.
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated

Proofs Involving Ordinary Least Squares Wikipedia

Ordinary Least Squares Estimators Derivation In Matrix Form Part 1 Youtube

Imp Partial Pressure And Mole Fraction Mole Fraction Pressure Math Equation

Pin On Freebies
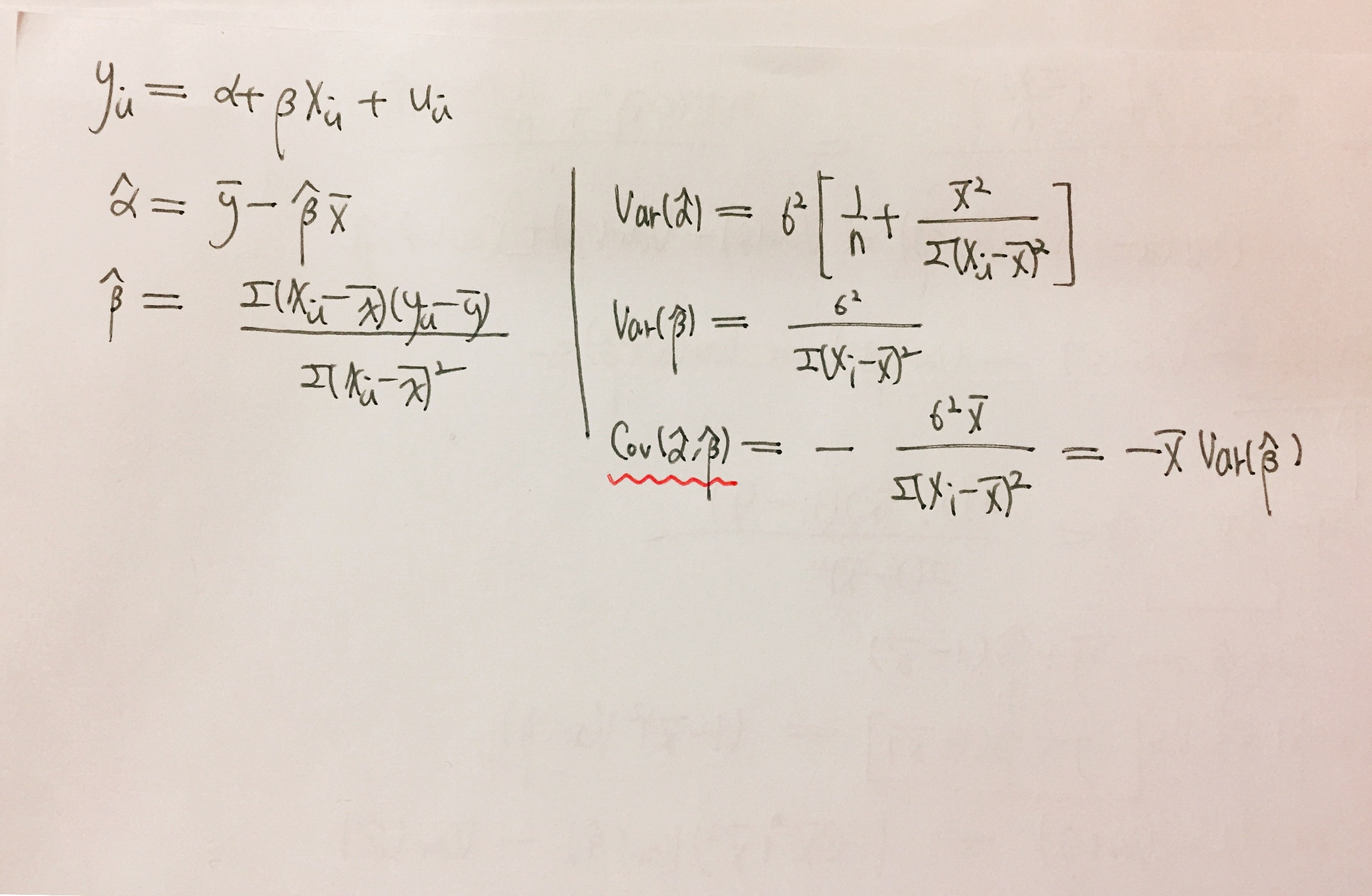
Covariance Between Estimates Of Slope And Intercept Cross Validated

James Craddock Gentleman Ghost Powers Invisibility Teleportation Skilled Marksman Energy Projection Intangibility Fire Shootin Simply Beautiful Gentleman Batman Year One Hero Arts

Deriving The Mean And Variance Of The Least Squares Slope Estimator In Simple Linear Regression Youtube
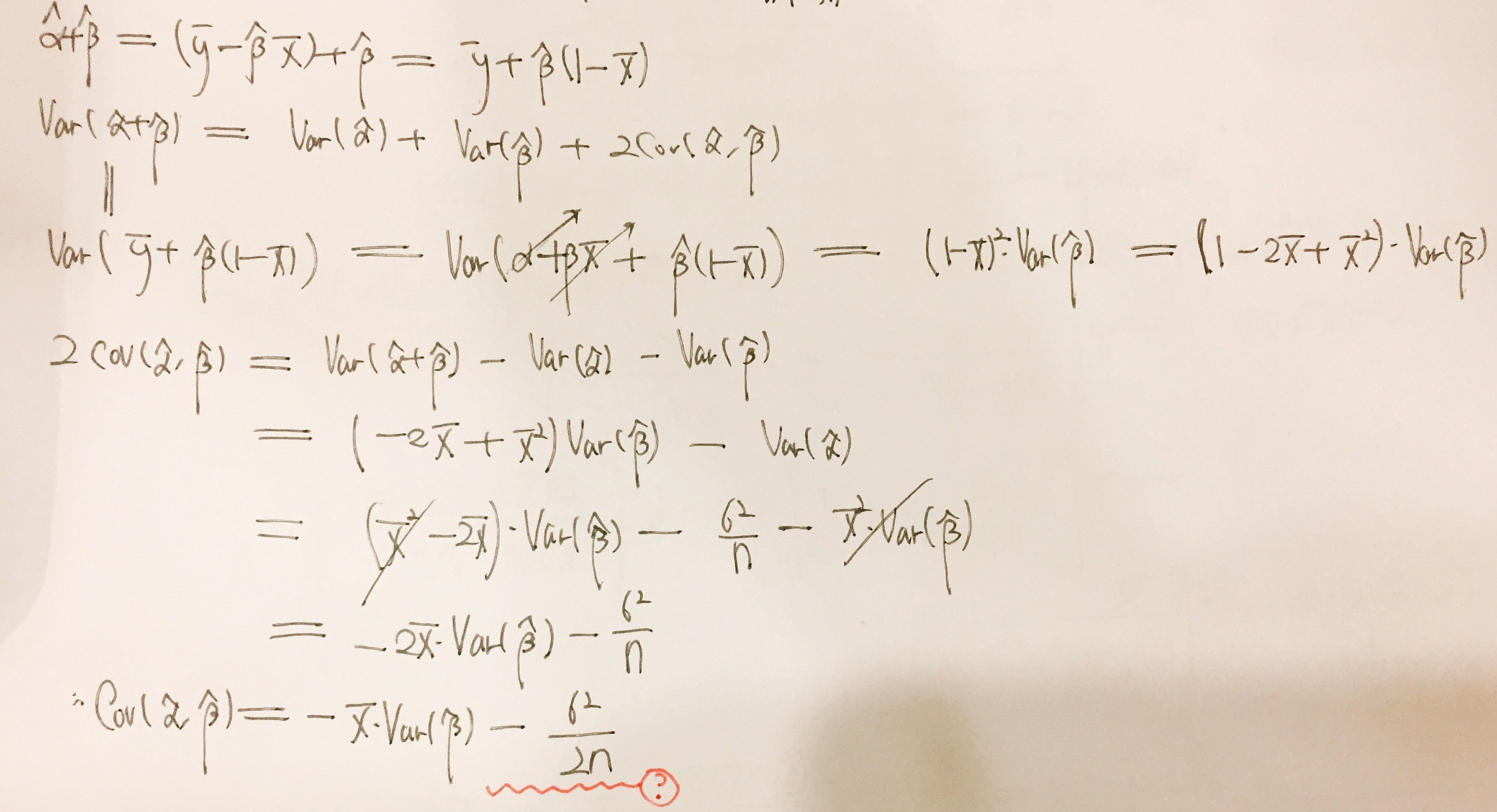
Covariance Between Estimates Of Slope And Intercept Cross Validated
Making Hats And Other Accents Bold Tex Latex Stack Exchange

Logitech Mx Keys And Mx Master 3 Mouse Getting Apple Versions In August Logitech Apple Keyboard

Natrabio Allergy Relief Non Drowsy 60 Tablets Asthma Treatment Allergy Relief Asthma Relief

Proofs Involving Ordinary Least Squares Wikipedia

