Hat Matrix Leverage Values
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated

The Plot Of Standardized Residuals Versus Hat Values With A Warning Download Scientific Diagram

Hat Matrix An Overview Sciencedirect Topics

Hat Matrix Freakonometrics
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated
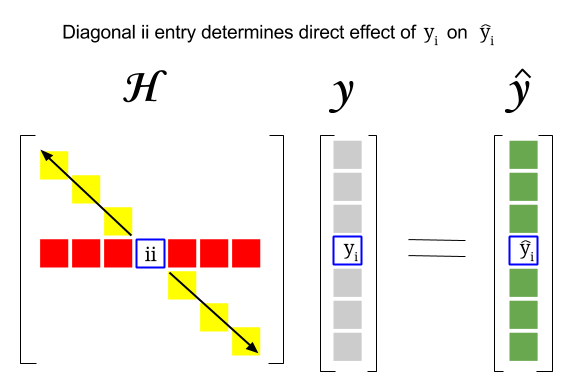
H X X X X t t1 Its a projection matrix.
Hat matrix leverage values. Yˆ is fitted value and e is residual the elements hii of H may be interpreted as the amount of leverage excreted by the ith observation yi on the ith fitted value ˆ yi. And why do we care about the hat matrix. It is useful for investigating whether one or more observations are outlying with regard to their X values and therefore might be excessively influencing the regression results.
Hat Matrix and Leverage Hat Matrix Purpose. The leverage is just hii from the hat matrix. Hat Matrix and Leverage Hat Matrix Purpose.
1 The condition for the diagonal elements of a projection matrix is 0 Hii 1 and for nondiagonal elements 1 Hij 1. The diagonal elements of the projection matrix are the leverages which describe the influence each response value has on the fitted value for that. Authors Michail Tsagris R implementation and documentation.
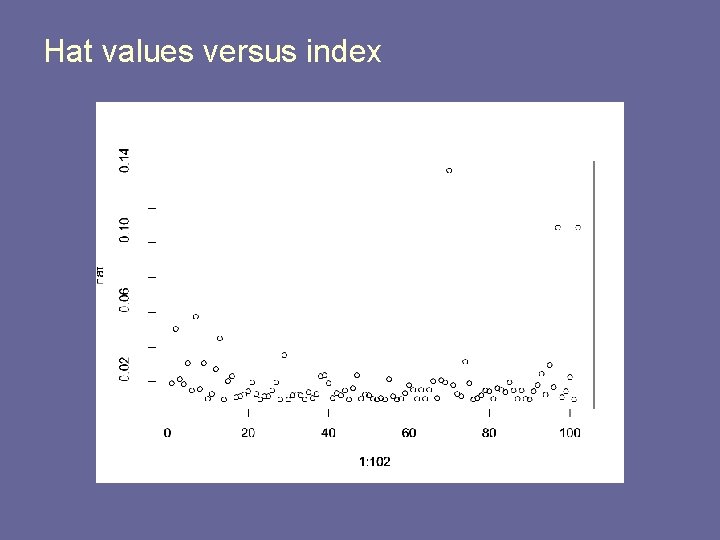
A vector with the diagonal Hat matrix values the leverage of each observation. Y X X X X X Y HYˆ βˆ t t1 So it is idempotent HH H and symmetric H Ht And E Y Y Y HY I H Y ˆ where I H is also a. Outlying observations tend to be large and there tends to be a gap between the outlying group and other leverage values.
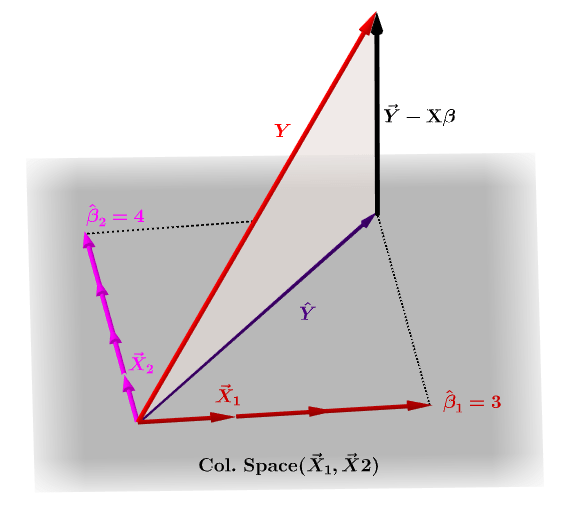
In statistics the projection matrix displaystyle sometimes also called the influence matrix or hat matrix displaystyle maps the vector of response values to the vector of fitted values. We did not call it hatvalues as R contains a built-in function with such a name. Diagonal elements denoted in literature as leverage have some properties which come from the symmetry and idempotency of matrix H.
The function returns the diagonal values of the Hat matrix used in linear regression. If 01 π 09 you can interpret the leverage values in a similar fashion as in the linear regression case ie. The matrix therefore transforms the -vector into the predicted values and is therefore termed the hat matrixThe hat matrix is symmetrix and it is a projection so that.

Properties Of Leverage Points In Regression With Proofs Note Typo Youtube

11 2 Using Leverages To Help Identify Extreme X Values Stat 501

Hat Matrix An Overview Sciencedirect Topics

The Plot Of Standardized Residuals Versus Hat Values With A Warning Download Scientific Diagram
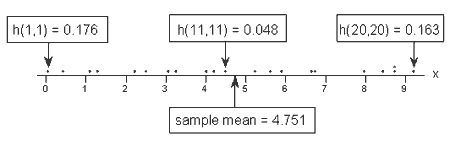
11 2 Using Leverages To Help Identify Extreme X Values Stat 501

7 For The Design Matrix 1 20 1 0 2 120 A Find The Chegg Com

50 Strategy And Management Models Powerpoint Templates Part 1 Slidesalad Powerpoint Templates Customer Journey Mapping Marketing Analysis

Linear Regression Chapter 9 Computational Statistics In The Earth Sciences

The Plot Of Standardized Residuals Versus Hat Values With A Warning Download Scientific Diagram

Linear Regression Chapter 9 Computational Statistics In The Earth Sciences

Lecture 13 Diagnostics In Mlr Variance Inflation Factors

Hat Matrix And Leverage Matlab Simulink

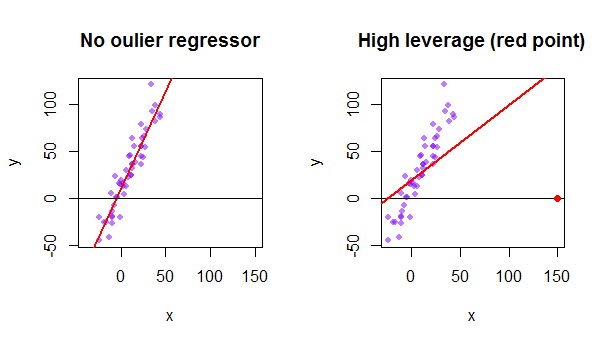
5 3 Outliers And Influential Cases

